The Krauthammer group publishes their work on deep learning-based multimodal fusion techniques to reduce annotation burden
Reducing Annotation Burden Through Multimodal Learning
This study examined deep learning-based multimodal fusion techniques for the combined classification of radiological images and associated text reports, comparing the classification performance of three prototypical multimodal fusion techniques. The experiments demonstrate the potential of multimodal fusion methods to yield competitive results using less training data than their unimodal counterparts. This suggests that the potential of multimodal learning decreases the need for labeled training data, which results in a lower annotation burden for domain experts.
See Lopez et al., Frontiers in Big Data
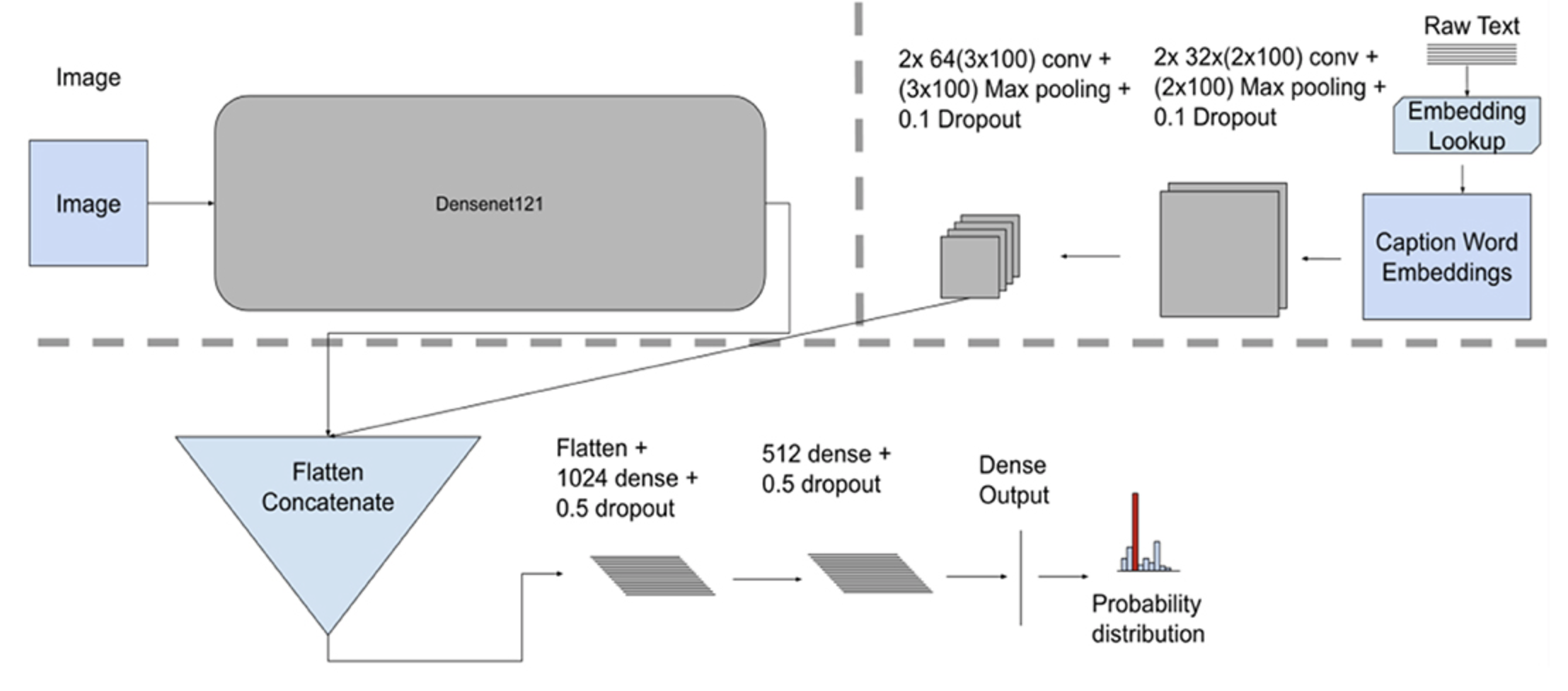
Figure 4. Model fusion model architecture, showing individual unimodal CNN feature extractors for images and text along with the concatenation fusion mechanism, a terminal network consisting of three dense layers.